美團O2O排序解決方案之數(shù)據(jù)處理服務
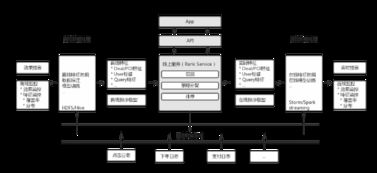
在美團O2O排序解決方案的線上實踐中,數(shù)據(jù)處理服務是排序系統(tǒng)的基石。它不僅負責海量實時和離線數(shù)據(jù)的處理,更直接影響到排序模型的準確性和實時性。以下是數(shù)據(jù)處理服務的核心模塊及其作用:
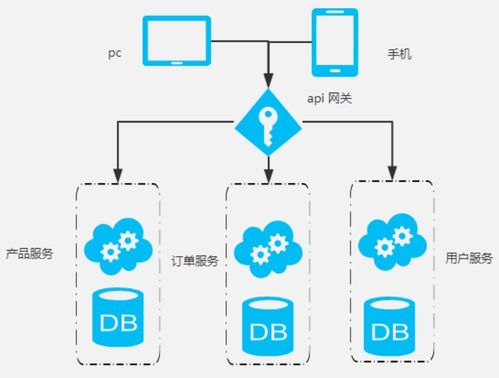
- 數(shù)據(jù)收集與接入:通過日志采集系統(tǒng)(如Flume、Kafka)實時收集用戶在美團平臺的點擊、下單、瀏覽等行為數(shù)據(jù),同時接入商家信息、商品詳情、地理位置等離線數(shù)據(jù),確保數(shù)據(jù)源的多樣性和完整性。
- 數(shù)據(jù)清洗與特征工程:對原始數(shù)據(jù)進行清洗,去除異常值和噪聲,并通過特征工程提取關鍵特征,如用戶偏好特征、商家熱度特征、時間上下文特征等。這一步驟借助分布式計算框架(如Spark)高效完成,為排序模型提供高質量輸入。
- 實時數(shù)據(jù)處理:利用流處理技術(如Flink)及時處理用戶實時行為數(shù)據(jù),快速更新特征和模型參數(shù)。例如,當用戶頻繁搜索某類商家時,系統(tǒng)能立即調整排序結果,提升用戶體驗。
- 數(shù)據(jù)存儲與同步:處理后的數(shù)據(jù)存儲于高性能數(shù)據(jù)庫(如HBase、Redis)中,支持低延遲查詢。同時,通過數(shù)據(jù)同步工具確保離線數(shù)據(jù)和在線數(shù)據(jù)的一致性,避免模型偏差。
- 監(jiān)控與容錯機制:建立完善的監(jiān)控系統(tǒng),實時跟蹤數(shù)據(jù)流量、處理延遲和錯誤率,并通過冗余設計和自動恢復機制保障服務高可用性。
數(shù)據(jù)處理服務的優(yōu)化直接推動了美團O2O排序效果的提升。未來,隨著AI技術的發(fā)展,美團將進一步融合深度學習和實時計算,打造更智能、高效的數(shù)據(jù)處理體系,為用戶提供更精準的本地生活服務推薦。
如若轉載,請注明出處:http://m.114vod.cn/product/4.html
更新時間:2026-02-19 20:15:01